
In this post we’ll go through an example application and see which methods and principles we can apply to build a robust application that is easy to maintain, extend, understand and use. In general, this is a subject with a much larger scope than a simple blog post can provide, so the content is neither complete nor exhaustive, but a selection of topics that I visited recently. We use an arbitrary business case where we can buy and sell resources on a market. Our example is implemented with Java using Spring Shell for a simple frontend representation. However, please keep in mind, even if technology you use operates differently, the principles stated in this post remain true for every language. Without further hesitation let’s start with an example of how our application works:

You can find the full application on GitHub.
In our application we have different commands we can interact with. By executing ‘help’ we can display all of them:
AVAILABLE COMMANDS (...) Market View buy: Buys the specified resource listPrices: Lists the current prices of all resources sell: Sells the specified resource User View info: Prints information about the user. inv, inventory: Lists the inventory of the user
As you can see, the commands are listed in two different categories: Market and User. These categories are our domains. Having a clear understanding of the domains of your application as well as a strict distinction between them provides several neat implications that separate well-designed architectures from others.
Domain Design
A robust code base has a clear distinction between its domains. But what are domains exactly? Wikipedia defines a Domain as “A domain is a field of study that defines a set of common requirements, terminology, and functionality […]”. So we should have an understanding of what our program does and how the parts belong together. One way of achieving that is by establishing a clear relationship between the data you need to solve your problem.
We know that our application allows users to buy and sell resources. So, considering this, we need the following data for our application:

We have an UserEntity that describes the actual user and holds the money and inventory of the user. The Inventory includes a map of ResourceIdVO (note: the VO stands for ValueObject. More on that later) to integer. A ResourceIdVO identifies a ResourceEntity which can have a name and a price. All ResourceEntity are aggregated in the Resources class. So the relationship between the models look like this:
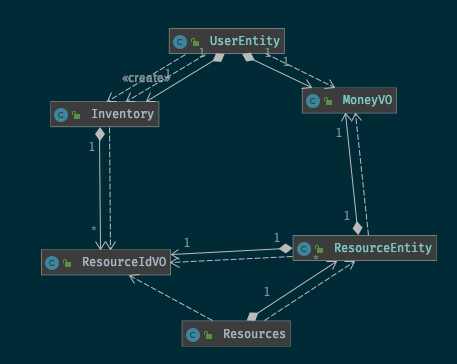
The diagram itself already indicates presence of two separate domains.. One domain seems to manage the resources another manages the user. For this example we can basically “draw a line” between the domains like that:

Please note that finding these domains does not follow any strict rule and you need to judge whether an object is better placed in one domain than another. A good example of that is the Money Class. It looks like a natural part of the User as well as the market domain and you could argue putting it in either one or another. In such cases, the location of a single class doesn’t usually have too much impact.
Distinct Value Objects and Entities
You might wonder why I introduced the ResourceIdVO that handles as a bridge between the ResourceEntity and the Inventory. To explain it we need to understand the two kinds of data you can distinguish between: An entity and a value object.
Entity
Entities are not defined by their attributes but by an identifier. As an example taken from the real world, you can say your apartment is an entity that describes all the furniture in it, but its identified by your address.
Value Object
On the other hand, a value object contains attributes and has no identifier. E.g. an apple is a value object that is described by its size, color and type but has no unique identification (but you could put a barcode on it, then it would be an entity). These objects should be treated as immutables, which mean they mustn’t change after creation. Many languages have built-in support for these objects like struct in C# or data class in Kotlin.
In our example a resource can have a price that changes. Therefore it must be an Entity. The choice whether your data must be treated as an entity or as a value object can be different from case to case. My recommendation would be to think about the necessary mutability of your object and generally prefer value objects over entities.
How to design your models
When you design your models (entity or value object) you should:
- take care that every operation on your object exclusively transforms, modifies, or returns values that are bound to this very instance of the object;
- provide a proper equals and hashcode implementation;
- provide factories.
Take care that every operation on your object exclusively transforms, modifies, or returns values that are bound to this very instance of the object
One very important aspect when you look at your model is that you distinguish between the data that it holds and the attributes that it offers. It’s crucial for every well-designed module that the data only holds a piece of information once. This means as soon as an information can be derived from the already-existing data, you should offer a view method in your model but should not store it in the actual data. The only reason to duplicate information should be performance considerations. If this is the case, first ponder whether it may be sufficient to exchange the current data with another transformation, and derive the original form out of the new one.
An example of this principle is implemented in our MoneyVO. We have the price as an attribute but the toString() method transforms the same information into a different representation:
public class MoneyVO {
private BigDecimal value;
[...]
@Override
public String toString() {
var format = new DecimalFormat("#0.00", new DecimalFormatSymbols(Locale.ENGLISH));
return format.format(value);
}
}
The model itself also needs to make sure that the data it holds is valid and every transformation on it is allowed by the contract of the class. For example the money a UserEntity has can’t be negative by its definition. So the UserEntity class needs to make sure that this transformation is not allowed.
public class UserEntity {
private MoneyVO money;
[...]
public void subtractMoney(MoneyVO value) throws NotEnoughMoneyException {
MoneyVO subtract = money.subtract(value);
if (subtract.isNegative()) {
throw new NotEnoughMoneyException(money, value);
}
money = subtract;
}
[...]
}
Provide a proper equals and hashcode implementation
Every model should implement equals() and hashcode(). This is important because other libraries depend on a proper implementation of both. E.g. you will get unexpected behaviors in all kind of Collections when it isn’t properly implemented.
For all entities it is simple to achieve, because by definition the identifier defines an entity. Therefore you just need to compare the identifier to decide whether an object is equal or not. For value objects you should have an implementation where every attribute is tested for equality respectively. Usually your IDE is able to able to generate both methods for you automatically. In many languages you even have a dedicated language feature that provides the implementation for you. For Java it’s worth mentioning project Lombok that provides an @EqualsAndHashCode annotation.
Provide factories
In order to have control over the creation of your entities you have dedicated factories for their creation. These enables you to restrict visibility of the entities constructors. For our ResourceEntity we can introduce a factory like this:
public class ResourceFactory {
private final ResourceIdGenerator resourceIdGenerator = new ResourceIdGenerator();
ResourceEntity create(String name, String price) {
return new ResourceEntity(resourceIdGenerator.newId(), name, new MoneyVO(price));
}
private class ResourceIdGenerator {
private AtomicInteger counter = new AtomicInteger(0);
ResourceIdVO newId() {
return new ResourceIdVO(counter.incrementAndGet());
}
}
}
The example factory now ensures that every resource we create has a unique identifier. Since the creation of the id is an implementation detail of the factory, we can – and should – describe it as a private inner class. The client that wants to create a new resource only needs to care about the actual business requirement and doesn’t need to know how we manage the resources in the background. Additionally, we are able to exchange the creation of our objects and make transformations or validations of our input if necessary.
The call to create a ResourceEntity is now straightforward:
resourceFactory.create("comic", 3),
Instead of implementing a dedicated class for your factory you can also consider providing static factory methods. To do this, you would put the create as a static method in the ResourceEntity. This makes it less verbose but also introduces the limitation that you wouldn’t be able to use injected dependencies in them.
Also consider offering a staged builder for your class that guides the client through the creation of your object.
Package Structure
For every domain you should have a corresponding package/namespace in your project. For our example project we end up with the following package structure:
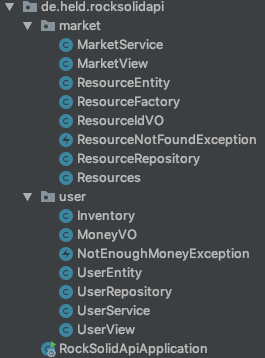
Every class that is related to these domains can now be placed in the respective package. You can consider using additional sub packages to organizing your classes like putting all models in sub-package. The downside of doing this in Java is that you can then no longer make use of package visibility because package visibility then because the parent package is not allowed to see the respective methods or classes.
Organizing your packages by domain will make it easy for other developers to understand how your application works, because there are three common ways in which a developer regularly searches the code:
- You know the name of a class → You use the search function of your IDE
- You know the interface or superclass of the class you search → You look in the hierarchy of your IDE
- Or you know to which feature the class you search belongs → In that case you can look at the package structure and find it there
Expose a thin but descriptive API
You should take special care when developing the API of your domain. The API is everything that can be seen and used from outside of your package. That includes every class, method, property or constant that has public or protected visibility. For everything your write you should consider making the visibility as low as necessary, but also you shouldn’t put the visibility as low as possible because exposing likely use cases can also improve the usability and maintainability of your domain. For example every constant in your code should be publicly visible. There is simply no need to hide them because no significant refactoring will be required when you change them. On the flip side, it’s way better for clients to refer to your constants instead of defining their own that mirror the ones in your domain.
As soon as you expose your API you should make it as easy to use as possible.
Provide class documentation
Every public class should have documentation about what the class is supposed to do. You should answer the following questions in your documentation:
- What does the class do?
- Which data does the class hold and/or manipulate?
- How should the class be used?
- Is your class thread safe?
Not all of the above questions need to be answered strictly on every class because for most classes the answers would be the same in your application. Just make sure that you document every difference to the common behavior in the application. E.g. there is no need to document thread safety in your application when you usually don’t need to care about if a class is thread safe or not. And if you design a class that explicitly needs to be thread safe, then mention it explicitly.
Write descriptive signatures
Following the concept of making your API as easy to use as possible you should document every publicly available method. By documentation I don’t necessarily mean the documentation between documentation tags in your code. The most important documentation is the signature of you method. Let’s have a look into the signature of a fictional method:
public int buy(String user1, String user2, String resource, int amount)
This signature doesn’t tell you much. You don’t know if user1 is buying from user2 and if resource is the name of the resource or maybe another property that identifies the resource? Also what does it return? The money you have after buying it? The new amount in your inventory? Or maybe an id of the transaction?
All of these questions can be solved by providing a more descriptive signature:
public TransactionId buy(UserId buyer, UserId seller, String resourceName, int amount)
Now all above questions are answered. You can understand without further documentation that the buyer buys “amount” many resources with the given resourceName from the seller and returns an id that can be used to identify this transaction.
In cases when you can’t or don’t want to introduce wrapper classes for your primitives you need to describe them properly in a documentation block.
Describe the contract of your methods
Every method has precise rules dictating how it should work, and be used. These rules are called the contract of the method. And this contract should be described as precisely as possible. For some methods it’s sufficient to document with only a proper signature, e.g. when you have getter and setters (without side effects and/or validation). However, for most methods it’s not possible to describe the contract by its signature alone. The contract should describe everything that is not intuitive and – if you’re in doubt – better describe more that you think is necessary. You should describe extreme values of parameters and side effects.
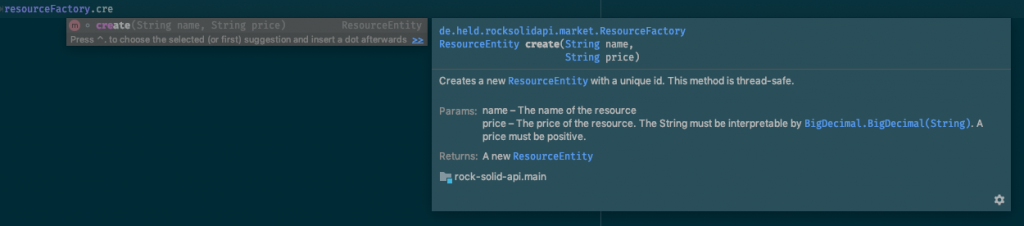
/**
* Creates a new {@link ResourceEntity} with a unique id. This method is thread-safe.
*
* @param name The name of the resource
* @param price The price of the resource. The String must be interpretable by
* {@link BigDecimal#BigDecimal(String)}. A price must be positive.
* @return A new {@link ResourceEntity}
*/
ResourceEntity create(String name, String price);
The example above defines multiple interesting constraints of the methods contract:
- The method must be thread-safe
- The id of the created entity is unique
- The price that is given into the method must be interpretable by BigDecimal
- The price must be positive
The caller of the code can now write and understand what the method does without leaving its context and jumping to the actual implementation.
If you try to express the same information in the signature you’d end up with something like:
ResourceEntity createWithUniqueIdThreadSafe(String name, String bigDecimalInterpretablePrice);
The example is very clumsy in its usage because usually you don’t need this information reading the client code. Also you lose nice IDE support by linking to other classes and methods.
Make Your Deepest Layer the Prettiest
The deeper you go in your architecture, the prettier your code should be. By this, I mean that code buried deep within the architecture should have more effort put into making it as maintainable as possible. This also applies to the test coverage. The deeper you go, the better your test coverage should be.
By sticking to this rule you accomplish faster development speed because changes become more expensive the deeper they are in your architecture. Imagine the simple example of adding a parameter to a method deep in your architecture. You’d need to supply this parameter now in every other layer that depends on your module, so this can potentially become tedious and more expensive than it should be.
Also, the deeper your module is located, the more likely it is that it gets used in many other places where the boundaries of your implementation will be stressed. Therefore, designing your module to handle these in the first place will reduce the effort of refactoring it and the chance of introducing bugs.
Conclusion
This article is by no means either a complete list of things you should consider when designing a module, nor should all of the principles be executed in a dogmatic way. In this article I have explained where the benefits of these principles lie and, with these in mind, you should judge how you want to apply them.
I recommend having the following two principles in mind when you think about your software design:
- Make it as easy as possible for the client to use your module
- The code must be easy to read, not to write – “the ratio of time spent reading versus writing is well over 10 to 1” (Robert C. Martin)
With these principles you will end up with a better design of your module and higher production speed as a result of it.