
Nowadays many companies, despite from their size, are choosing agile methodologies in order to build their teams. As a result they often end up with many smaller teams that are independent of each other.
At this point, teams should be able to plan, develop and deploy their own peace of software which would interact with other team’s applications or services, like it or not, they are building a kind of cloud infrastructure. To avoid chaos it’s a good idea to learn common patterns and reason for their existence.
When it comes to Spring developers, they have an option which is definitely worth checking out and that is Spring Cloud, I would like to quote their own definition here:
Spring Cloud provides tools for developers to quickly build some of the common patterns in distributed systems (e.g. configuration management, service discovery, circuit breakers, intelligent routing, micro-proxy, control bus, one-time tokens, global locks, leadership election, distributed sessions, cluster state). Coordination of distributed systems leads to boiler plate patterns, and using Spring Cloud developers can quickly stand up services and applications that implement those patterns. They will work well in any distributed environment, including the developer’s own laptop, bare metal data centers, and managed platforms such as Cloud Foundry.
Here are some of popular Spring Cloud features:
- Distributed/versioned configuration *
- Service registration and discovery *
- Routing
- Service-to-service calls *
- Load balancing *
- Circuit Breakers
- Global locks
- Distributed messaging
Using several of these features (marked with *), I will create the below services step by step with minimal configuration:
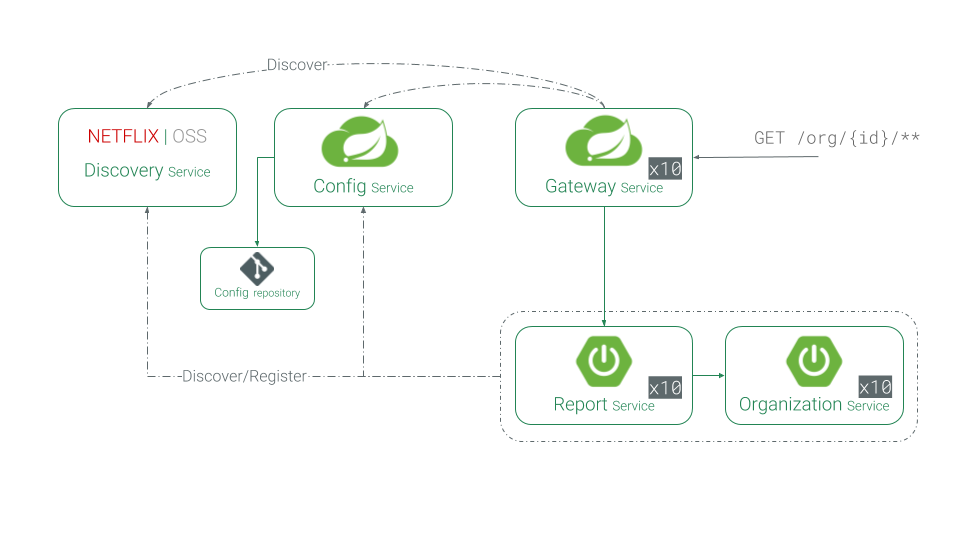
- x10 refers to more than one instance of that service.
- Config Service provides configuration for other services (by reading a git repository)
- Report Service and Organization Service receive their configurations from Config Service. They need to be registered to our Discovery Service to communicate with each other.
- Gateway Service is entrance to the distributed system. It’ll handle clients’ requests and find the desired services to call. To keep this article simple I will exclude the implementation of this service but you can read more about Spring Cloud’s gateway and take a look at their examples here: https://spring.io/projects/spring-cloud-gateway
Table of Contents:
- Config Service: Spring cloud solution to have centralized configuration across your microservices
- Organization Service: A simple standalone service to demonstrate some functionalities
- Config service – refresh: Describing a way to refresh configuration values without restarting services
- Netflix OSS: Contribution of Netflix to Spring cloud
- Discovery Service: Your microservices register themselves here so they’ll be able to find each other
- Report Service: Another simple standalone service to demonstrate some functionalities
- Feign – Declarative Rest Client: Magical way to call other service’s endpoints
- Conclusion: Should I really use it?
Note: In order to keep it simple, I will cover important parts of implementation and flow with screenshots and simplified figures. You can find more details by following the gitlab link to the implementation and documentation page at the end of each section.
Config Service
The Config Service pulls configurations from a git repository and make them available for other services.
The git repository could be local or any kind of online services like github or gitlab, with or without authorizations.
All you need is to add spring-cloud-config-server dependency and @EnableConfigServer annotation to your application then define your git repository URL in the application’s properties file.
I have defined the config git repository as https://github.com/pezhman32/spring-cloud-demo-config/ here you will find a file named organization-service.properties. To clarify: organization-service is the value of spring.application.name property in our Organization Service‘s properties file which we will cover later in this article.
Once you boot the application you will notice in the logs that it tries to pull configurations from the git repository:
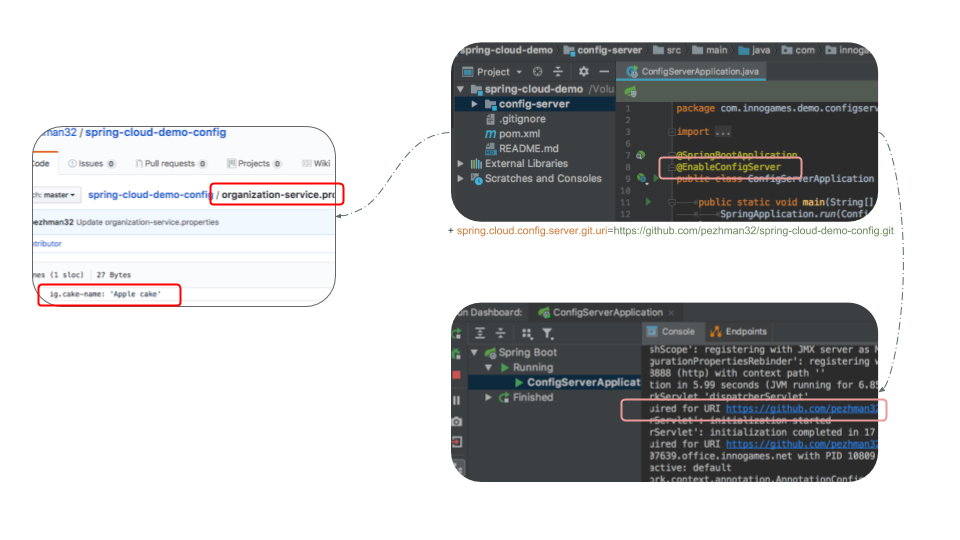
Let’s keep this service up and running for now…
Supporting links:
More information about spring-cloud-config: https://cloud.spring.io/spring-cloud-config/
Organization Service
Simple service to demonstrate pulling configurations from config-server.
While booting the application (if we already have spring-cloud-starter-config dependency available) it will attempt to connect to the config-service and pull the configuration values from the Config Service (uses predefined default address and port).
Without any extra effort I can now inject the value of a defined property in the git repository to my organization-service (in this case it was ig.cake-name). I have created a simple REST endpoint to output the value, by calling the endpoint I receive “Apple Cake” as a response which is only defined in the git repository:
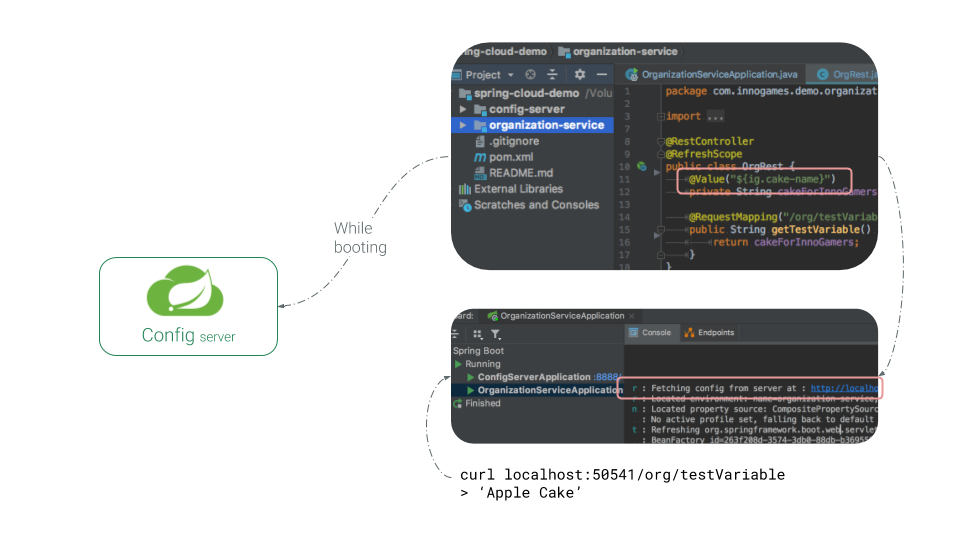
Supporting Links:
- organization-service.properties content: https://github.com/pezhman32/spring-cloud-demo-config/blob/master/organization-service.properties
- Full source code: https://gitlab.innogames.de/dev-blog/spring-cloud-demo/tree/master/organization-service
Config Service – Refresh
As Spring developer, you are fully aware that if you want to update your variables in the properties files you require a restart of the application for the changes to take effect. This is due to those values being injected to beans during the boot process.
Imagine an environment with couple of instances of your microservice where you need to update a minor value in application.properties, for example a change in database connection, you will need to restart all instances to reflect these changes which is an expensive task.
Having Spring Could Config’s @RefreshScope annotation in place, you can call an endpoint on your microservice and it will re-query config-service for updates (if there are any). It will then re-create the beans that are effected which would then apply any changes.
But should you call the endpoint on all instances of your service? not necessarily, you can trigger an update from config-service and it can send updates through rabbitmq or similar tools to all related services. You could also use hooks to listen to your updates on the config git repository then you don’t need to even call that endpoint 🙂
The following figure shows that I have updated my value in the git repository to “Cheese Cake”. Then I can call the /actuator/refresh endpoint on my organization-service. It will then re-query config-service and accordingly config-service would re-query the git repository.
Now if I call the endpoint from the previous section once again, it will return the newly updated value as response: “Cheese Cake”
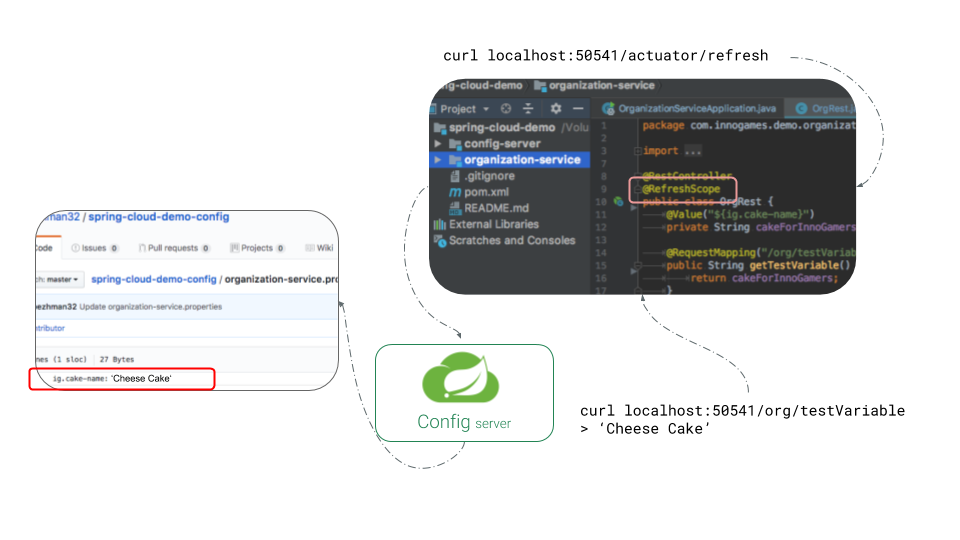
Supporting Links:
- More information about @RefreshScope: https://cloud.spring.io/spring-cloud-static/spring-cloud.html#_refresh_scope
- Source code for REST endpoint: https://gitlab.innogames.de/dev-blog/spring-cloud-demo/blob/master/organization-service/src/main/java/com/innogames/demo/organizationservice/OrgRest.java
Netflix OSS (Open Source Software)
When Netflix was developing its own cloud solutions there was no fancy solution like Kubernetes around. They decided to implement as much as they could in the application layer and afterwards they open sourced part of their solution. It is officially available in Spring’s documentation and it is easy and nice to play with. Looking into the most important parts we can find the following topics:
Eureka as Service Discovery
Ribbon as Load Balancer
Hystrix as Circuit Breaker
Feign as Declarative REST Client
You can find more information about Netflix OSS here: https://spring.io/projects/spring-cloud-netflix
I’ll try to quickly demonstrate Eureka, Feign and Ribbon with the following simple example.
Discovery Service
Service Discovery is one of the key tenets of microservice-based architecture. Trying to hand-configure each client or some form of convention can be difficult to achieve and can be brittle. Eureka is the Netflix Service Discovery Server and Client. The server can be configured and deployed to be highly available, with each server replicating state about the registered services to the others.
To setup the discovery service, we can simply add @EnableEurekaServer annotation (from spring-cloud-starter-netflix-eureka-server dependency) to our discovery-service application.
Once you start the application, you can see a simple eureka dashboard in the browser, it contains basic information about the environment and connected clients.
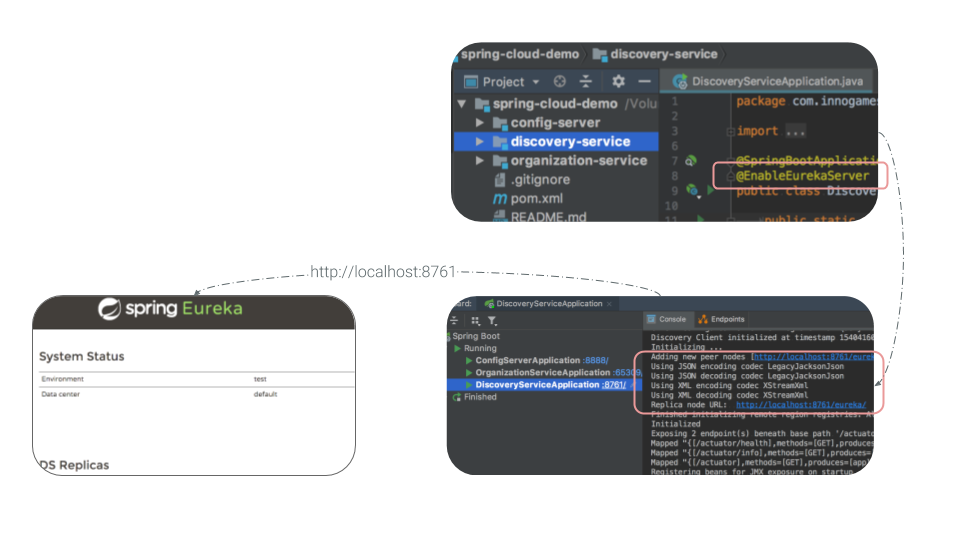
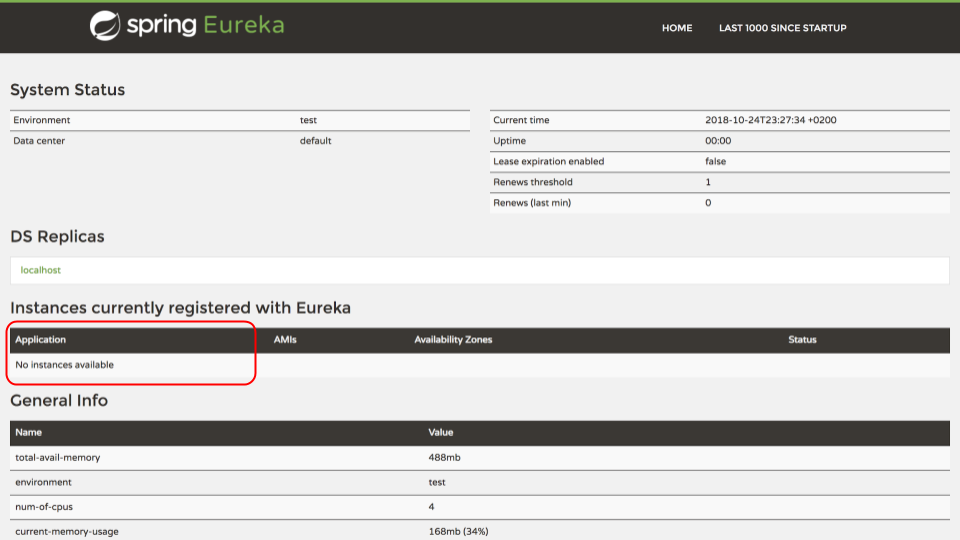
Following screenshot shows that no client is connected to the newly configured discovery-service at the moment:
To setup clients, we need to add @EnableEurekaClient (from spring-cloud-starter-netflix-eureka-client dependency) to our client applications, in this case they are organization-service and report-service.
Once we start the client application it will try to report its state every few seconds to the eureka server (discovery-service). This process could report in the opposite direction meaning that the eureka server could also ask for client’s state every few seconds but in this case the eureka server should be aware of client’s address (but this may not be the case all of the time).
If you refresh eureka server’s dashboard, you can see the connected client.
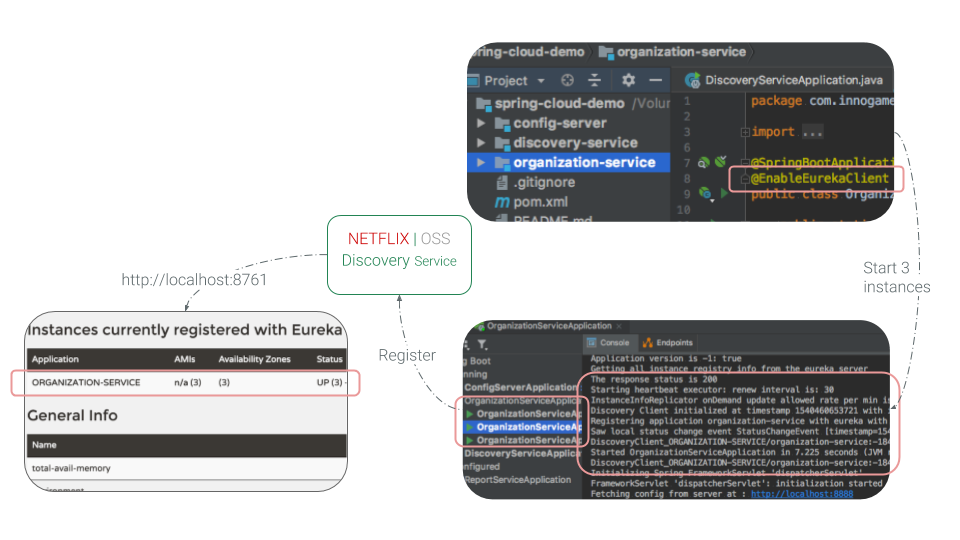
All provided information on the dashboard are also retrieved via REST endpoints so you could even create your own dashboard monitoring service.
Supporting Links:
- Full source code for discovery-service: https://gitlab.innogames.de/dev-blog/spring-cloud-demo/tree/master/discovery-service
- More information about Eureka server: https://cloud.spring.io/spring-cloud-netflix/multi/multi_spring-cloud-eureka-server.html
Report Service
Report Service is just another sample microservice! It identifies the organization-service and calls its endpoints. In this example I’m using report-service to demonstrate how clients find each other using Eureka service discovery and how they can call each other’s endpoints using “declarative REST client” (Feign).
We can use dependency injection to autowire DiscoveryClient. We can pass the service’s name (like organization-service) to its getInstances method to get a list of all available instances of that service. In this case if we have 2 instances of an organization-service the method will return a list with 2 elements representing details of those 2 instances. We can get the first element in the list and call its endpoint using a restTemplate as shown below:
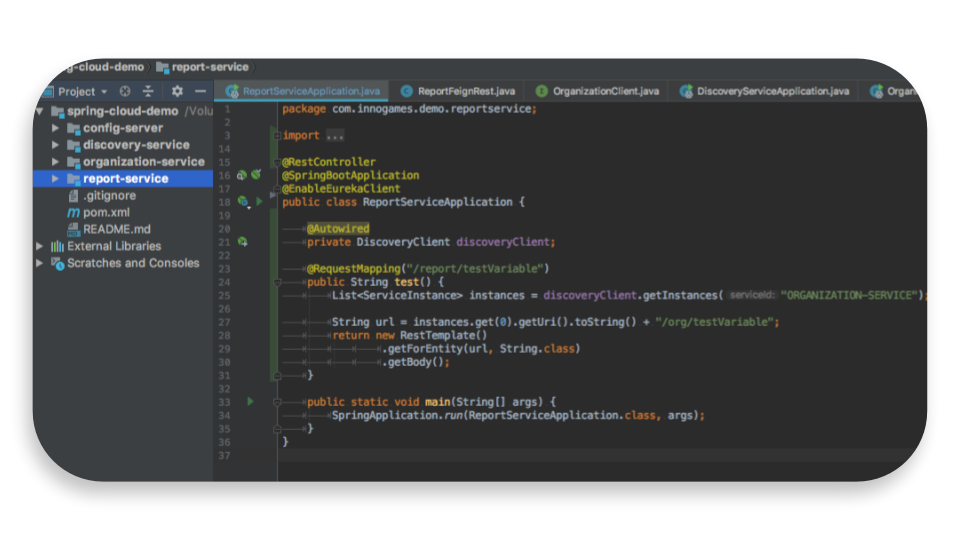
As you may remember the endpoint of organization-service that we called from report-service returned the property value from git repository (Cheese Cake).
Following figure is an overview of the process:
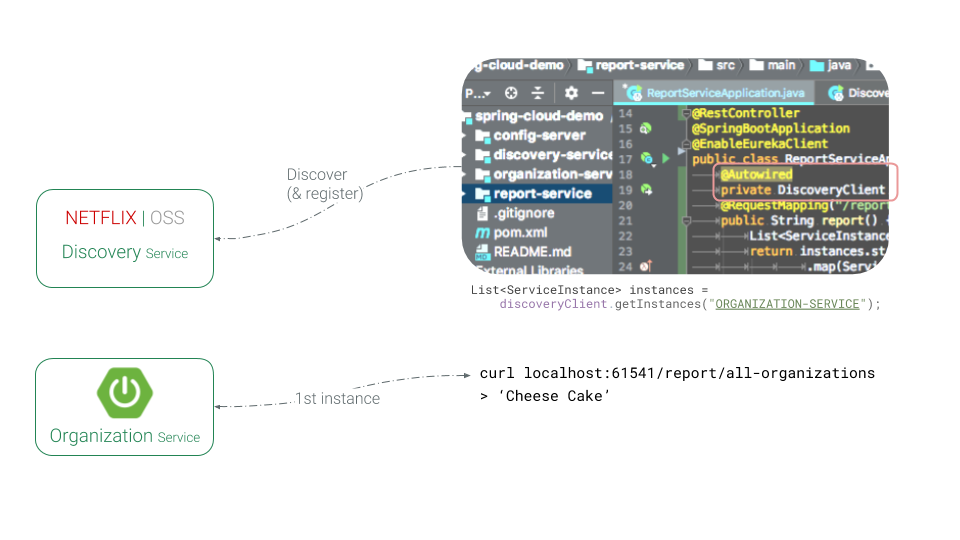
In last step we tried to find organization service, pick one instance and call its endpoint. We can see that it is flexible and powerful as we have full control inside the application but there is also a lot of manual work to done. Such as:
- It’s not convenient enough to call other service’s endpoints with RestTemplate
- Why pick the first instance? we need a load balancer…
- What if selected instance is not available at that moment? we need latency and fault-tolerant implementation
So there is a lot to improve for that piece of code but there are already few nice existing solutions for the above mentioned problems, We’ll review some of those in the next section.
Supporting Links:
- Full Source code for report-service: https://gitlab.innogames.de/dev-blog/spring-cloud-demo/tree/master/report-service
- More information about Eureka clients: https://cloud.spring.io/spring-cloud-netflix/multi/multi__service_discovery_eureka_clients.html
Feign – Declarative Rest Client
This is where it gets exciting for lazy developers you can replace all the above implementation by just declaring the rest client. Exactly how you would do it with JPA and Hibernate. By defining an interface and a @FeignClient annotation.
Everything including service discovery, load balancer, REST calls and fault tolerance solutions will work out of the box. Take a look at following interface’s definition:
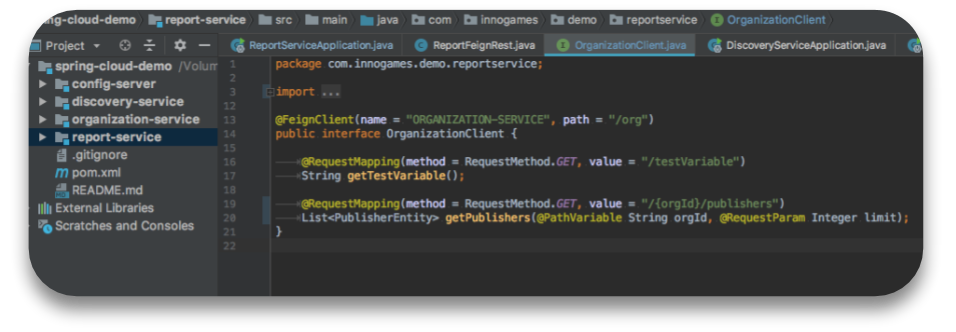
As You can see, a Feign client has been declared for organization-service with a URL root path of /org. There are 2 service calls to demonstrate how flexible and easy it is. You can have POST, PUT with request body and other http methods as well.
The following figure shows how you can work with this client in report-service to call organization-service endpoints:
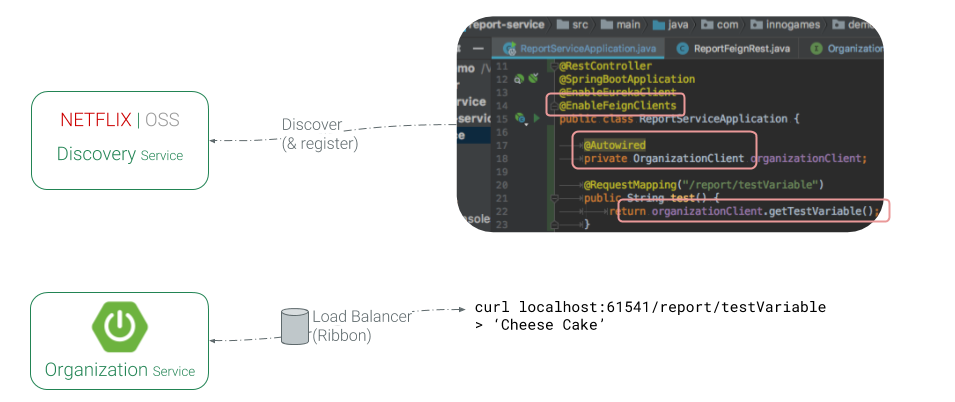
So when the report-service application boots it will try to register to the discovery-service and at the same time it will get a list of available services.
Having @EnableFeignClients is necessary to enable our Feign clients (as mentioned, they are defined by @FeignClient annotation). Using DI (dependency injection) we can easily autowire OrganizationClient (which was defined by an interface recently) and call its methods. It will then use Ribbon as loadbalancer (by default) to select a live organization-service instance each time you call it.
As you saw it will easily bring us native style for our cloud environment thus we don’t have to deal with ugly restTemplate calls and care about load balancing.
There are more interesting details that you can configure, like retrying if a request failed, enabling Hystrix which is Netflix’s circuit breaker and a fault-tolerant solution. Take a look at the following documentation for more details:
https://cloud.spring.io/spring-cloud-netflix/multi/multi_spring-cloud-feign.html
Conclusion:
In order to keep it efficient what I demonstrated here was quite short however Spring cloud has a lot more to offer. I highly recommend you to take a look at their titles. You might find several interesting existing solutions for your problems:
https://spring.io/projects/spring-cloud
In the end, should we really consider it? I would say it depends on the problem, development and production environments.
As an example, if you are deploying your applications to Kubernetes, there is no need for service discovery, load balancer and many other implementations because you’ll have the solution in Kubernetes which is language/framework independent.
Good thing is that Spring Cloud is modular. As such you might be able to use one of the offered solution without using any of the others.
Let’s summarize with some pros and cons:
Pros:
- Nice if you have all your microservices implemented with Spring
- Application level handled. Which means it brings flexibility with the implementation
- Easy to implement, configure and extend
- Easy to setup in development environments. You can run the whole package from load balancer to service discovery just by booting your services
- Offers alternatives under the hood
- Modular design
And lastly a couple of cons:
- Application level handled which means it brings complexity to the application level
- Less to offer in multi-language environments, if you have services implemented with other languages you’ll need lots of manual implementations there
Thanks for taking the time to read. Feel free to comment your thoughts and questions or send them as message over linkedIn: https://www.linkedin.com/in/pezhman32